大数据与Hadoop
一、大数据导论
1、企业数据分析方向
数据是什么:指对客观事件进行记录并可以鉴别的符号
怎么产生数据:对客观事物计量和记录产生数据
分析数据的作用:把隐藏在数据背后的信息集中提炼出来,总结出所研究对象的内在规律,帮助管理者进行有效的判断和决策
数据分析的三大方向:现状分析(当下),原因分析(过去),预测分析(未来)
离线分析:面向历史,在时间维度成批次性变化,也叫批处理
实时分析:分析实时的数据,秒级毫秒级分析,也叫流式计算
机器学习:侧重数学算法的运用,预测未来发生的事情
2、数据分析基本步骤
1、明确分析目的和思路
2、数据收集:采集 or 传输
3、数据预处理:数据的格式化
4、数据分析
5、数据展现:数据可视化
6、报告撰写:《xxx数据分析报告》
一切围绕着数据
3、大数据时代
大数据:指无法在一定时间范围内,用常规软件工具进行捕捉、管理和处理的数据集合
5V特征:
1、数据体量大
2、种类来源多样化
3、低价值密度
4、速度快
5、数据的质量
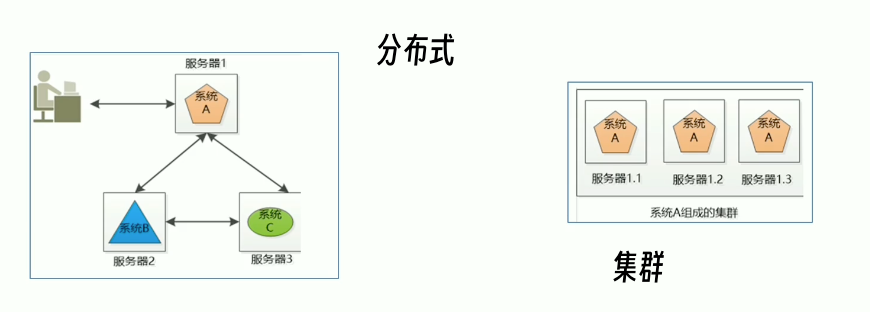
4、分布式与集群
分布式:多台机器,每台机器部署不同组件
集群:多台机器,每台机器部署相同组件
二、Hadoop概述
1、介绍
Hadoop是Apache软件基金会的开源软件
hadoop核心组件:
- Hadoop HDFS(分布式文件存储系统):解决海量数据存储
- Hadoop YARN (集群资源管理和任务调度框架):解决资源任务调度
- Hadoop MapReduce(分布式计算框架):解决海量数据计算
广义上Hadoop指的是围绕Hadoop打造的大数据生态圈
2、简史
Hadoop之父:Doug Cutting
Hadoop起源于Apache Lucene子项目:Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎
3、现状
HDFS作为为分布式文件存储系统,处在生态圈的底层与核心地位
YARN作为分布式通用的集群资源管理系统和任务调度平台 ,支撑各种计算引擎运行,保证了Hadoop地位
MapReduce作为大数据生态圈第一代分布式计算引擎,由于自身设计的模型所产生的弊端 ,导致企业一线几乎不再直接使用MapReduce进行编程处理,但是很多软件的底层依然在使用MapReduce引擎来处理数据
4、优点
扩容能力:可以分布在各个节点
成本低:部署普通廉价的机器组成集群来处理大数据
效率高:通过并发数据,可以在节点之间动态并行的移动数据
可靠性:能自动维护数据的多份复制,并且在任务失败后能自动地重新部署计算任务
通用性(与业务脱钩)、简单性
5、版本
开源社区版:官方发行版本,兼容性稳定性一般
商业发行版:稳定性好、得加钱...
Cloudera、Hortonworks
6、架构变迁
Hadoop 1.0
HDFS(分布式文件存储)
MapReduce(资源管理和分布式数据处理)
Hadoop 2.0
HDFS(分布式文件存储)
MapReduce (分布式数据处理)
YARN(集群资源管理、任务调度)
Hadoop 3.0
精简内核、类路径隔离、she11脚本重构
Hadoop HDFS:EC纠删码、多NameNode支持
Hadoop MapReduce:任务本地化优化、 内存参数自动推断
Hadoop YARN:Timeline Service v2、队列配置