线性回归模型与梯度下降法
线性回归模型与枚举法
线性回归模型定义:

- w:权重
- b:偏置
mermaid
graph LR
x[特征 x]
y[工资 y]
w[w1, w2, w3, ..., b]
学历 --> x --> 线性回归模型
专业 --> x
... --> x
y --> 线性回归模型 --> w损失函数:用于计算输出和真实值之间的误差
线性回归的目标:寻找一组参数w、b,使损失函数最小。(预测结果接近真实数据)
如何求w、b --> 枚举法求解:猜呗!慢慢猜w是多少!😅(不现实)
最小二乘法
满足二次函数,通过 的方式可以求出极值。(多个w可以求偏导数)
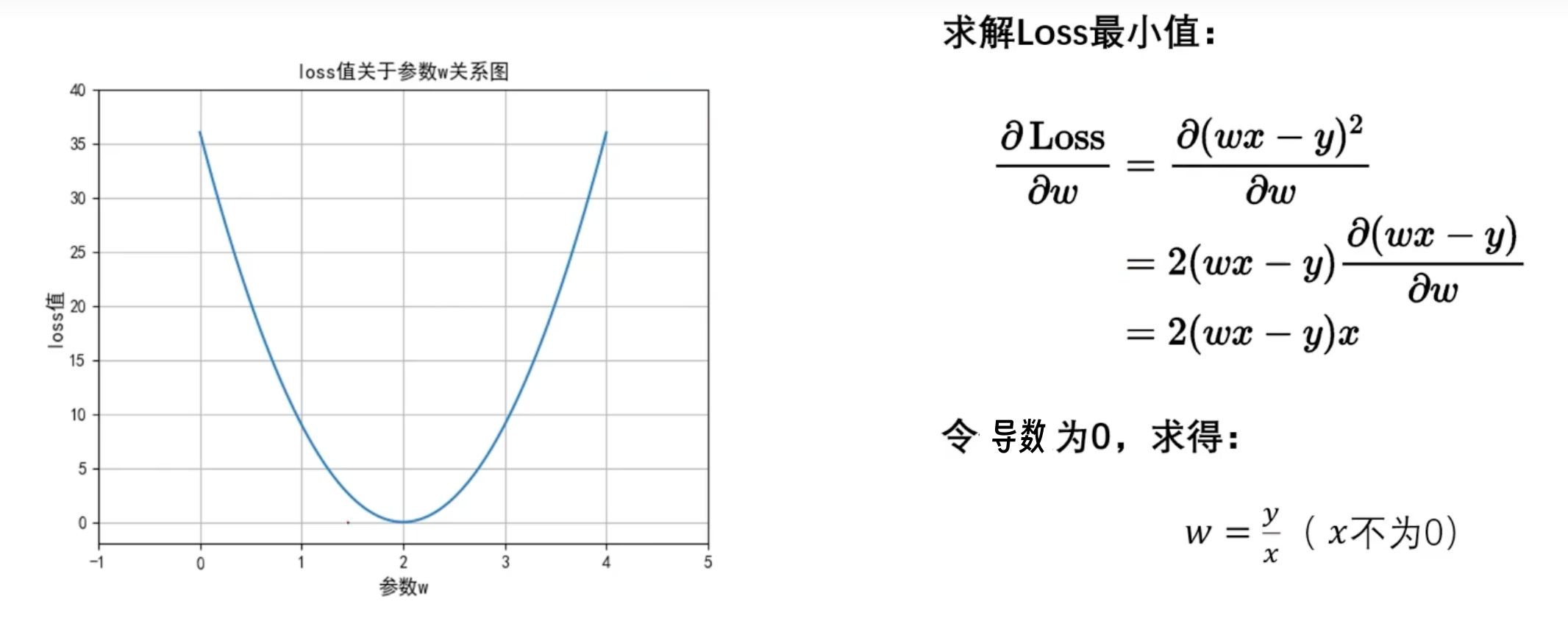
😋 不要怕数学。学好数学并不难。
对于向量形式:
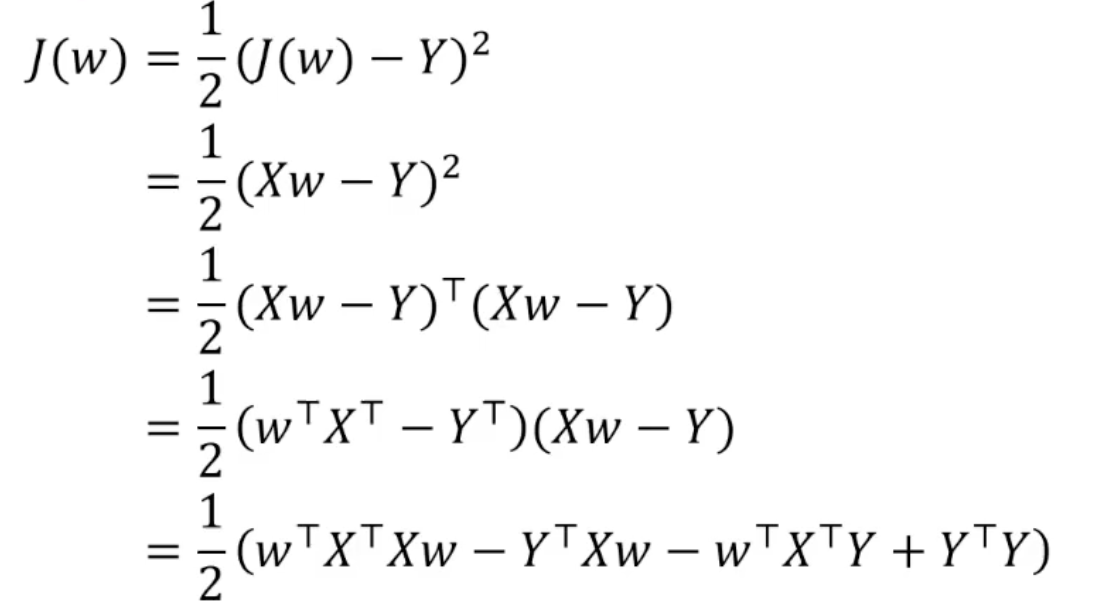
利用 导数为零 得到极小值。

矩阵可逆的充要条件之一是其行列式不为0,当矩阵的行列式等于0时,矩阵一定不可逆。
存在问题:由于 不一定存在,所以最小二乘法不一定能获取到最小值。
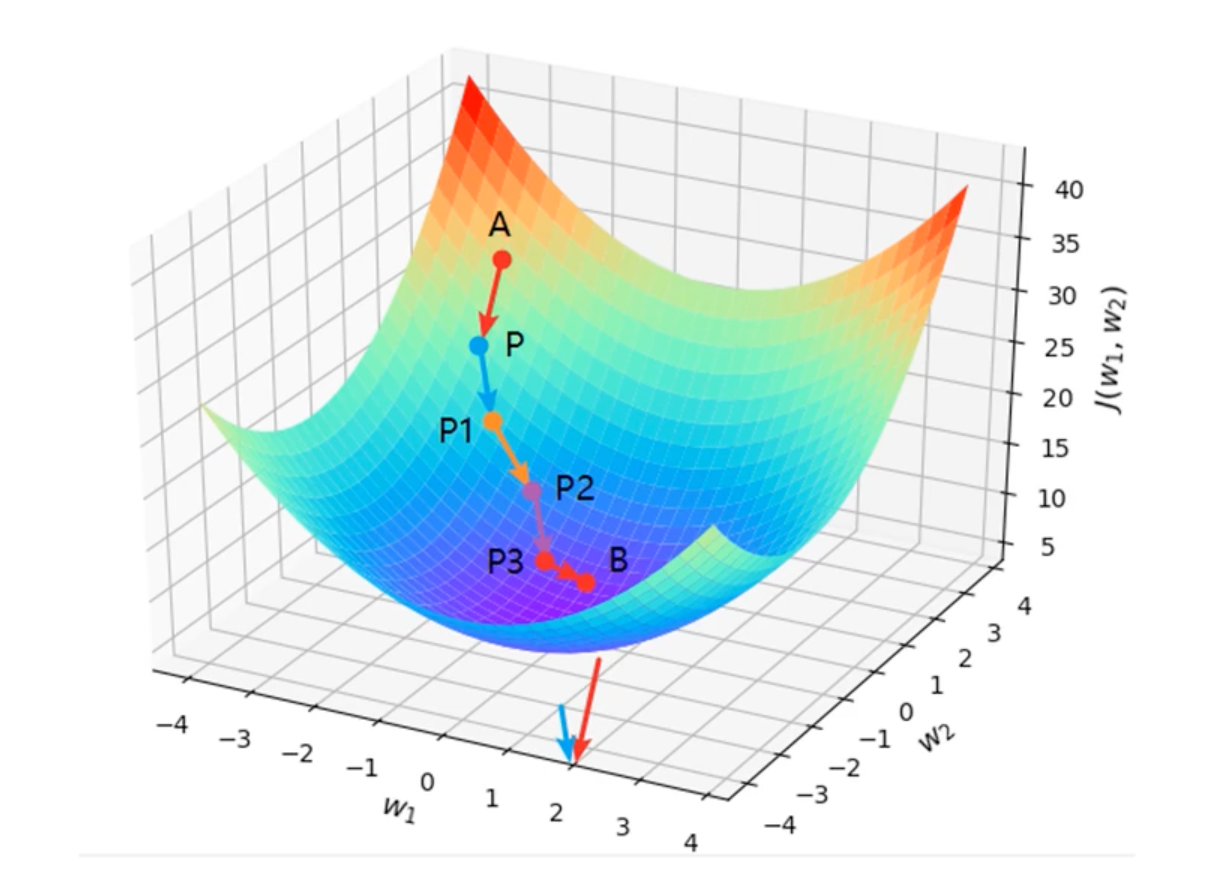
⭐️ 梯度下降法
带有方向的穷举法
核心:方向、步伐
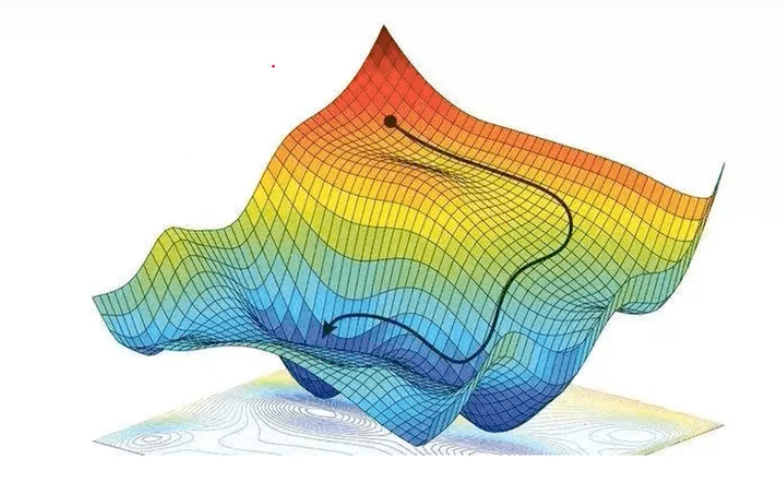
梯度下降法参数更新的计算公式:
- :学习率(步伐)
- :当前值的导数值,取负数(下降的方向)
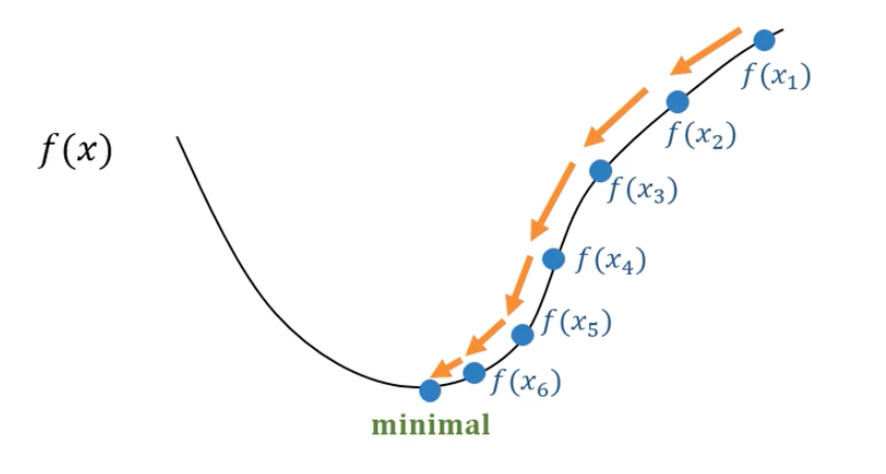
小案例:

学习率较为重要,常常为经验值(0.01、0.1...)。
多参数求解:求偏导数
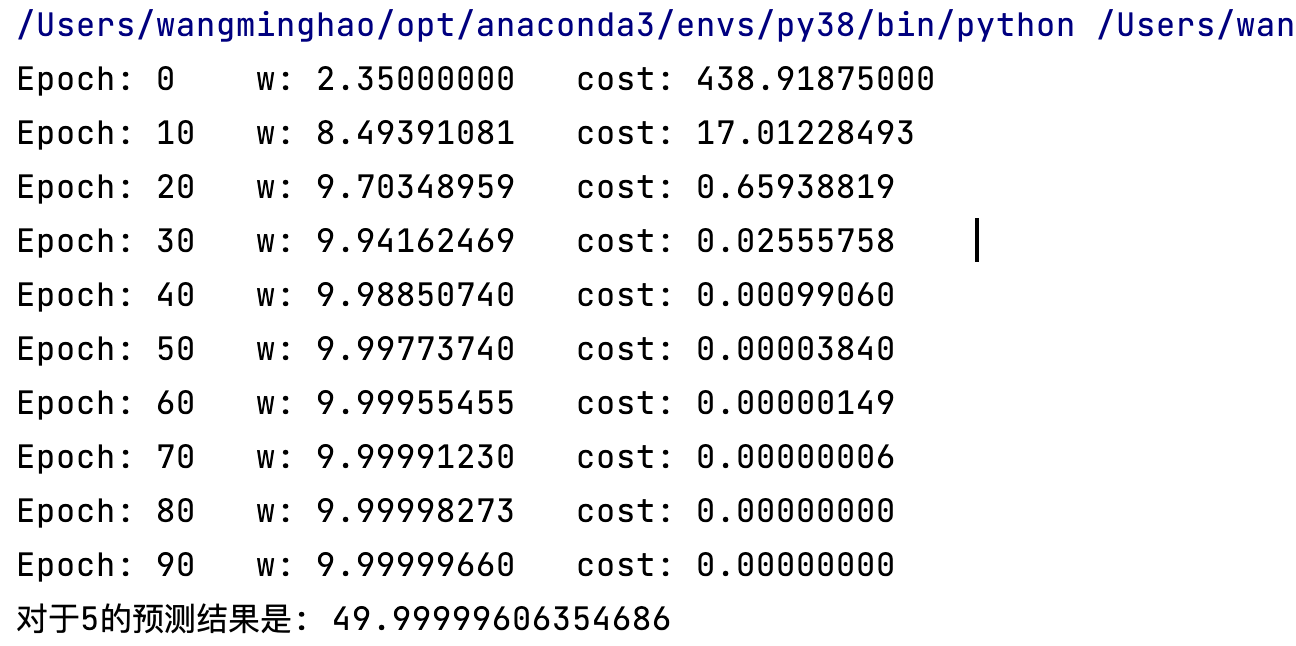
代码实现
深度学习过程:
- 定义模型(线性回归、逻辑回归...)
- 数据:特征 (x) 与标签 (y)
- 损失函数:定义预测值与真实值的差距
- 梯度下降法更新参数(权重w和偏置b)
python
# 线性回归模型
def forward(x):
# y' = wx
return w * x
# 损失函数 (多个数值求平均损失)
def cost(x, y):
cost_val = 0
for xx, yy in zip(x, y):
# loss = (wx - y)^2
cost_val += (xx * w - yy) ** 2
return cost_val / len(x)
# 梯度下降 (多个数值求平均损失)
def gradient(x, y):
# 梯度值
grad = 0
for xx, yy in zip(x, y):
# w = w - a(dLoss(w) / dw)
# dLoss(w) / dw = 2x(wx - y)
grad += 2 * xx * (w * xx - yy)
return grad / len(x)
if __name__ == '__main__':
# 数据集:特征
x_data = [1, 2, 3, 4]
# 数据集:标签
y_data = [10, 20, 30, 40]
# 学习率 (经验值)
learn_rating = 0.01
# 初始化参数 w (随机值/经验值)
w = 1
# 多次更新w参数
for epoch in range(100):
w -= learn_rating * gradient(x_data, y_data)
cost_num = cost(x_data, y_data)
if epoch % 10 == 0:
print(f'Epoch: {epoch}\tw: {w:.8f}\tcost: {cost_num:.8f}\t')
# 使用更新过的 w 进行预测
test_data = 5
print(f'对于5的预测结果是: {forward(5)}')