卷积神经网络
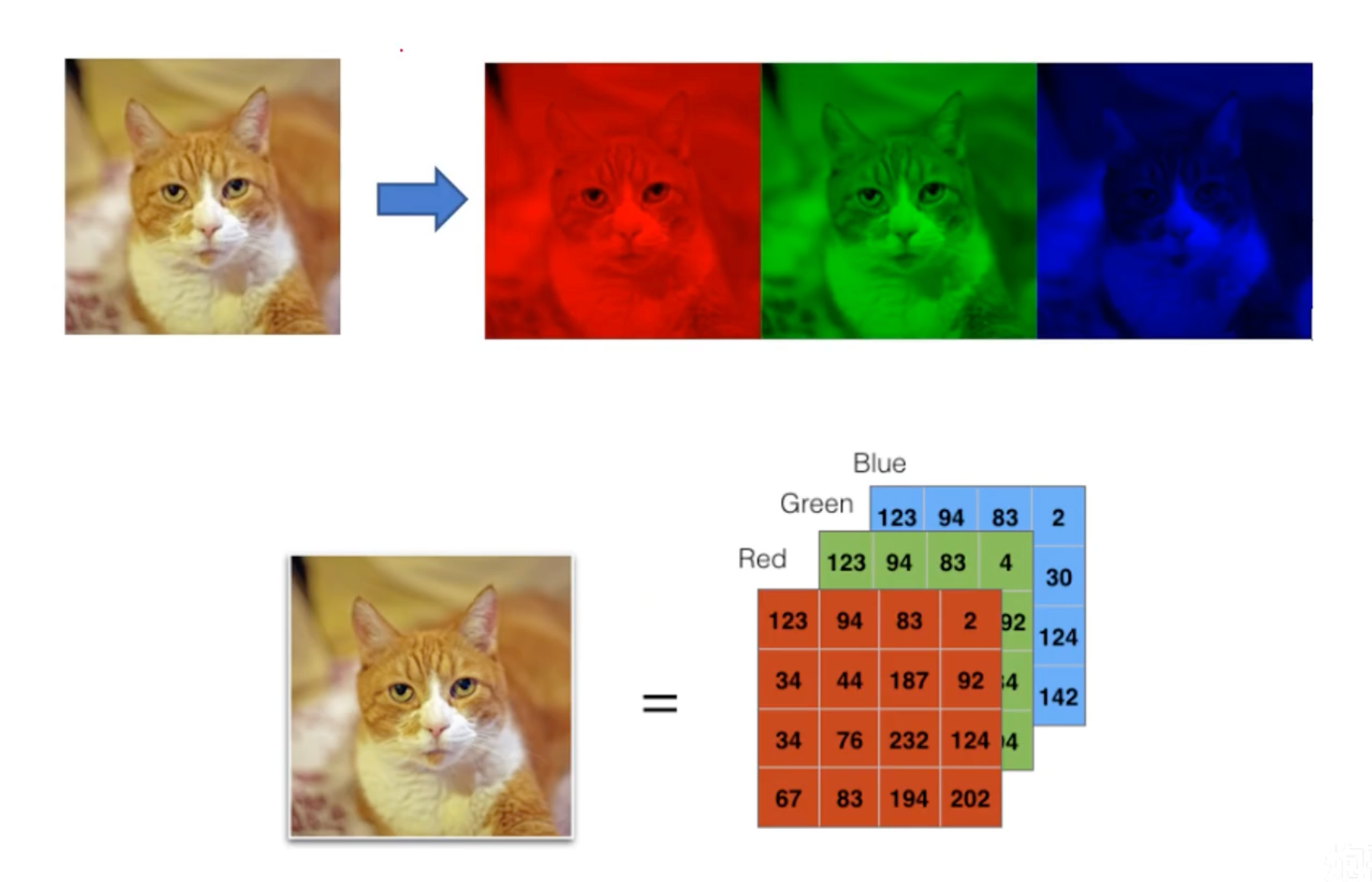
图像的本质
图像是一个或多个数值矩阵(亮度、RGB)
灰度图:一个存有亮度信息的矩阵

彩色图:三个矩阵分别存储RGB色彩信息
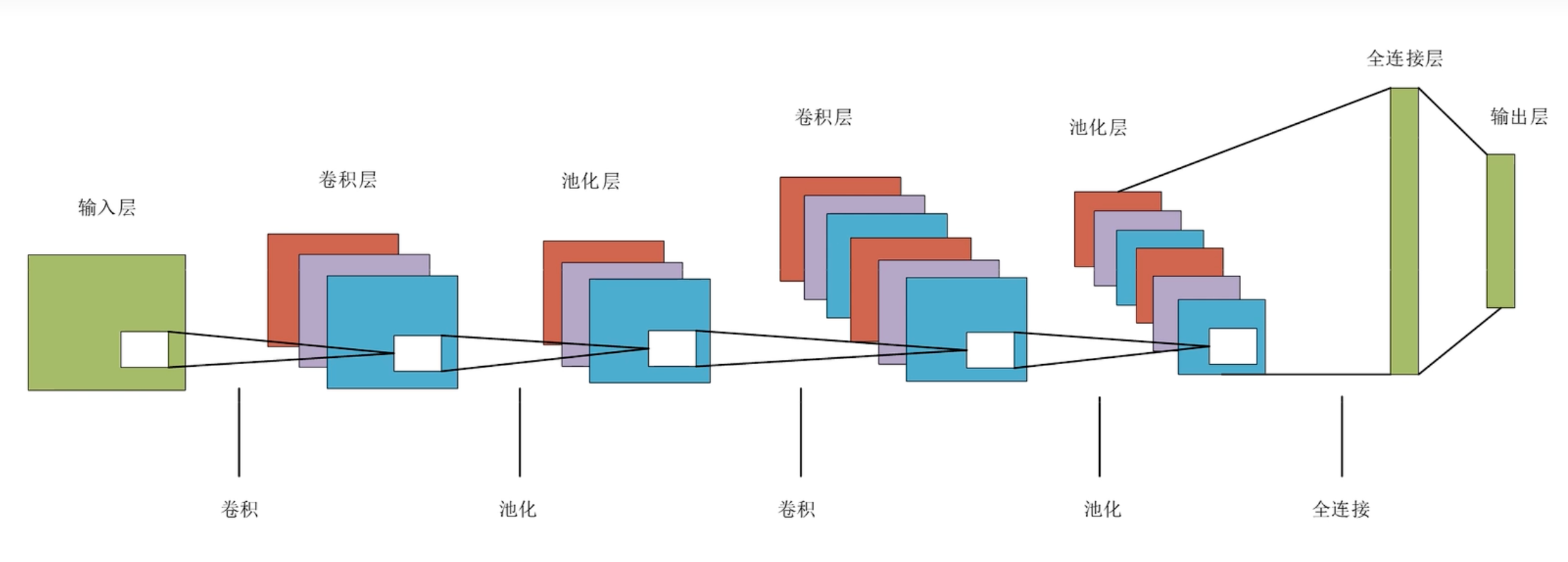
卷积神经网络结构
卷积神经网络结构特征
- 卷积:将单通道变成多通道,修改原始矩阵的大小
- 池化:通道数不变,不一定改变原始矩阵的大小
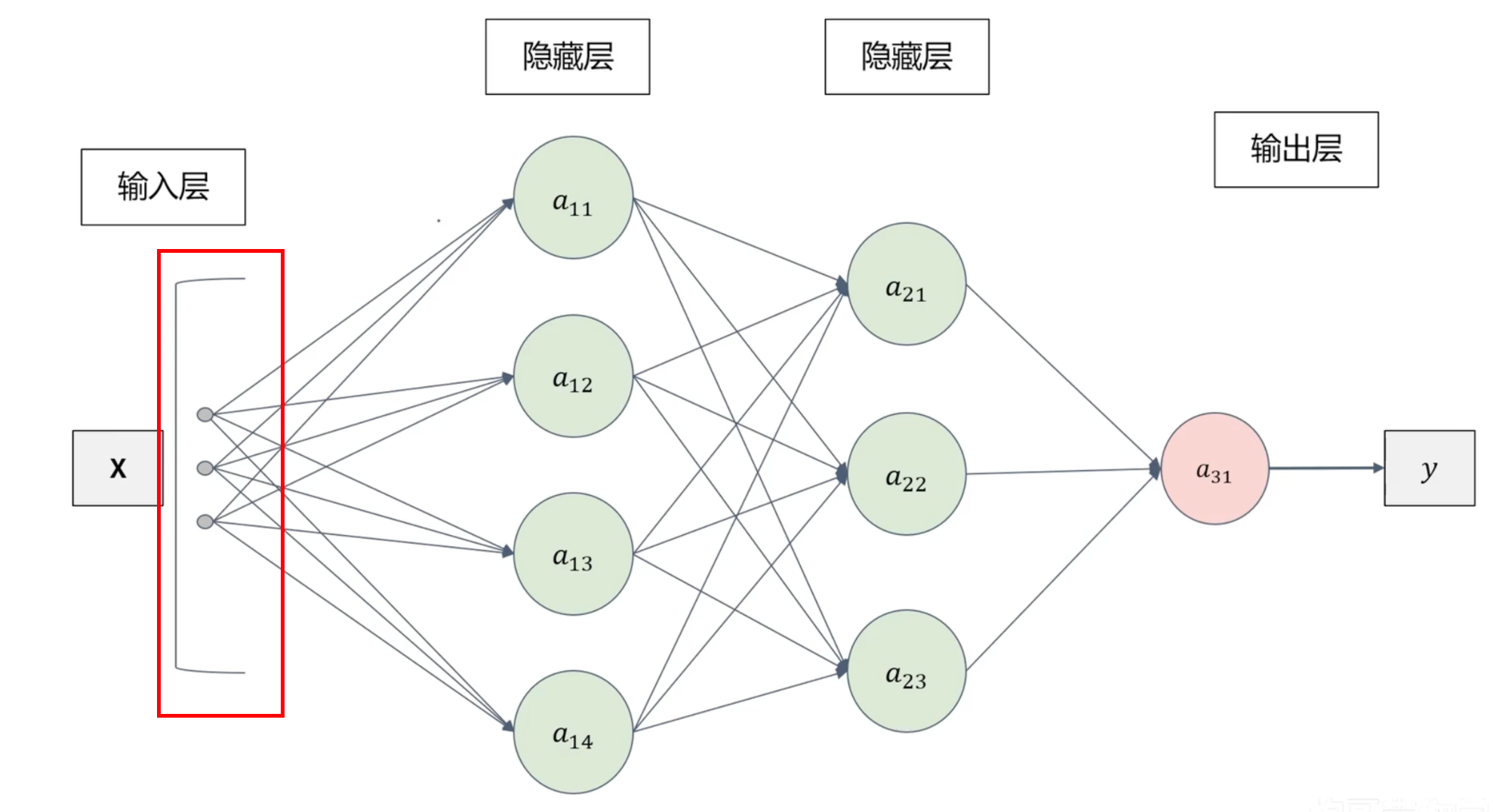
全连接神经网络存在的问题
全连接神经网络的输入必须是线性(条状)的
把图片切割成条状会损失图片的空间信息 → 精度低
卷积神经网络的参数比全连接神经网络参数少,避免过拟合,计算量小。
卷积运算
卷积
- 输入:特征
- 卷积核:权重 w
- 偏置:b

相比于全连接神经网络模型( 个权重参数),卷积神经网络只有4个参数(权重共享)。计算量减小,避免过拟合问题。
权重共享:是指在神经网络中多个部分共享相同权重。
这意味着不同部分的神经元使用相同的权重来进行计算,这样可以减少需要训练的参数数量,节省计算资源,并且有时可以提高模型的泛化能力。
填充
填充:在输入数据周围添加额外的像素值(通常是0),以便在进行卷积运算时能够保持输入和输出的尺寸一致或者满足特定的需求。

步幅
步幅:指在进行卷积操作时,滑动卷积核的间隔距离。可以想象成在图像上移动卷积核的步长。
如果步幅为1,那么卷积核每次移动一个像素;如果步幅为2,那么卷积核每次移动两个像素。
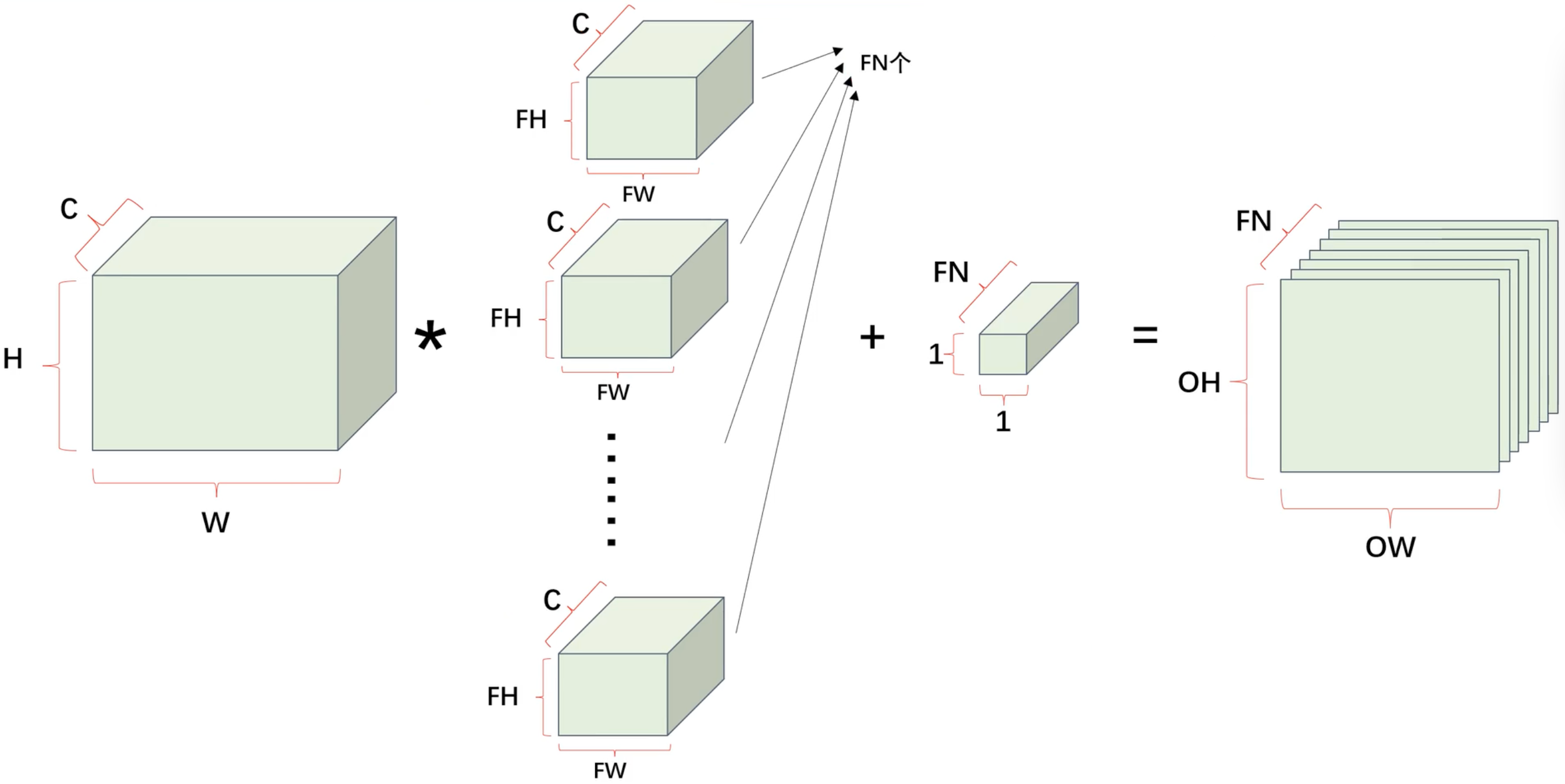
卷积后的特征图大小
- H:特征图的高
- P:填充的范围
- FH:卷积核的高
- S:步幅
- OH:卷积运算后的高
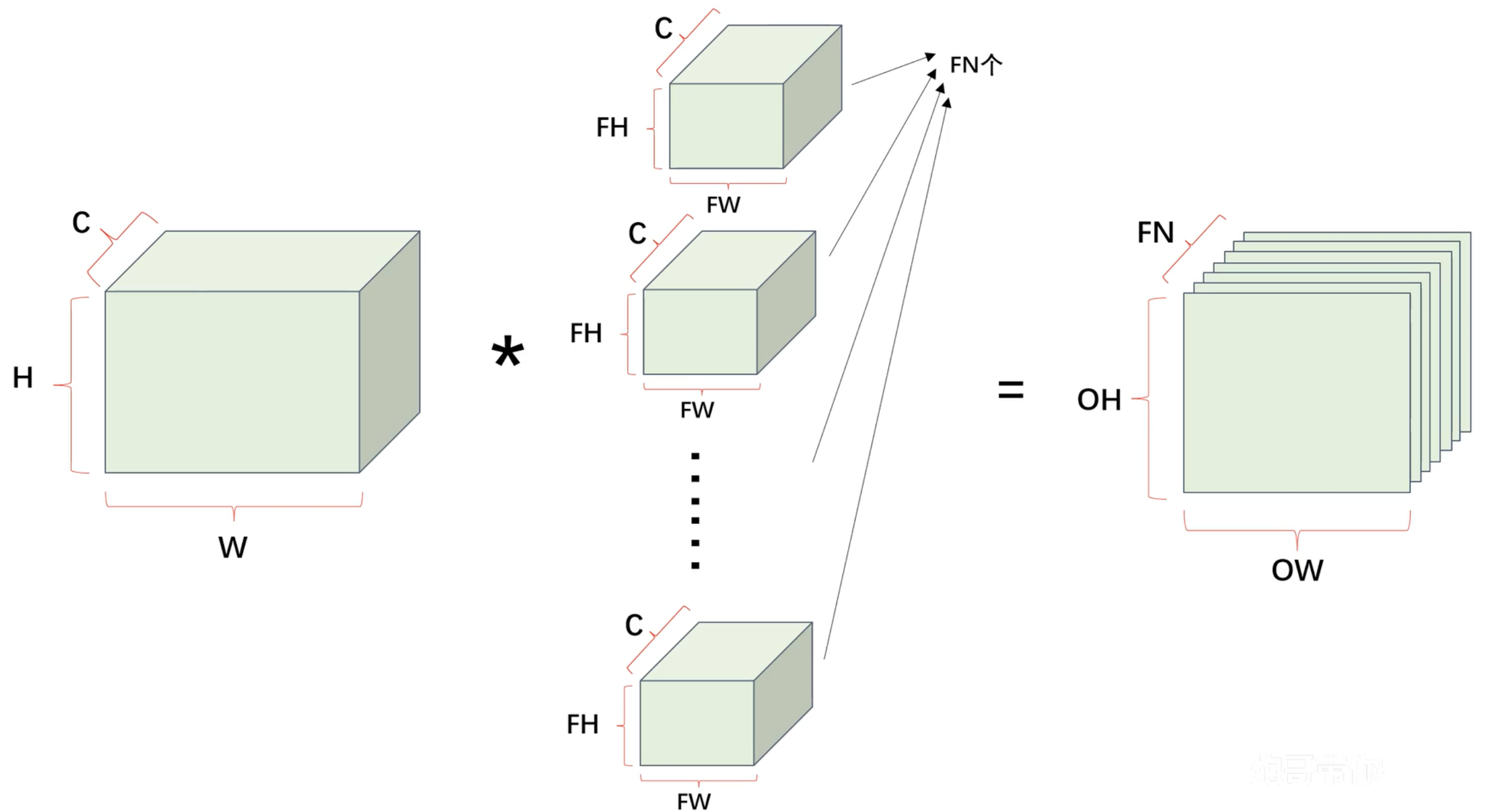
卷积层 - 多通道卷积

使用立方体表示卷积运算

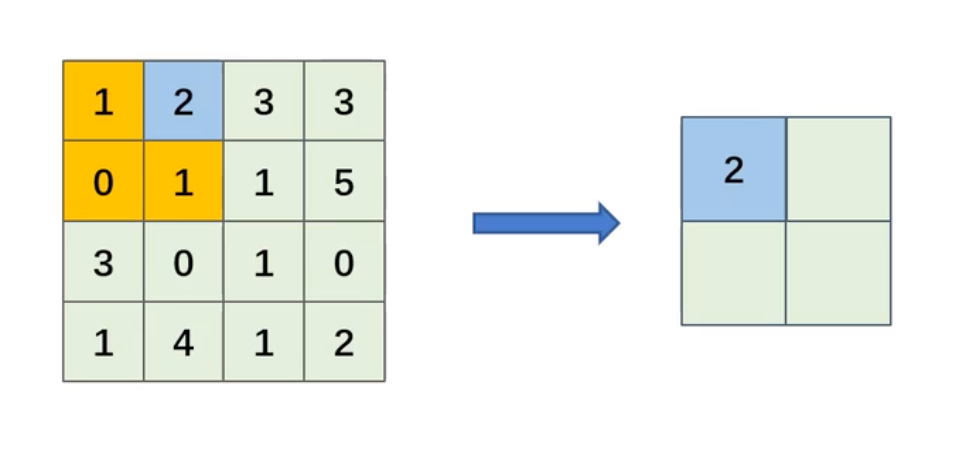
池化运算
最大池化
- 池化核:每次池化运算的区域大小
- 步伐:滑动池化核的间隔距离
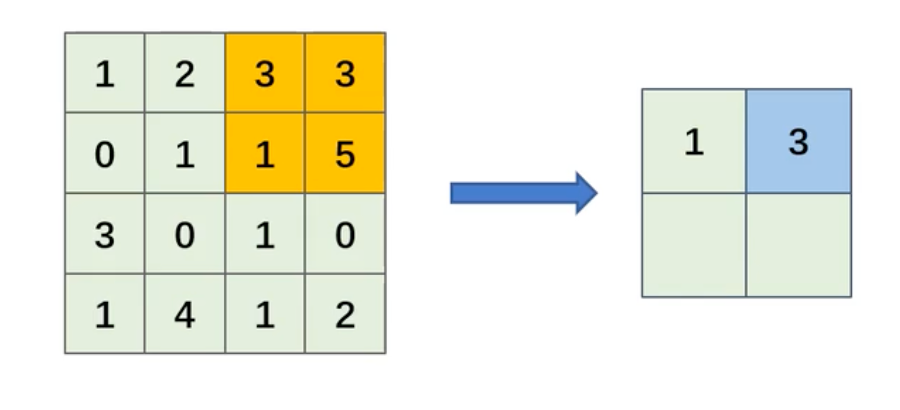
平均池化
池化的优点
输入的数据不仅有长和高,还有通道。但是池化不会对输入特征图的通道进行改变,池化操作是按通道独立进行计算的。
池化层对微小的位置变化具有鲁棒性,使模型更加的健壮。当输入特征数据发现微小的变化的时候,输出的特征图的结果仍然是一样的。

池化后的特征图大小
- H:特征图的高
- P:填充的范围
- FH:池化核的高
- S:步幅
- OH:池化运算后的高
LENET实现
LENET模型介绍
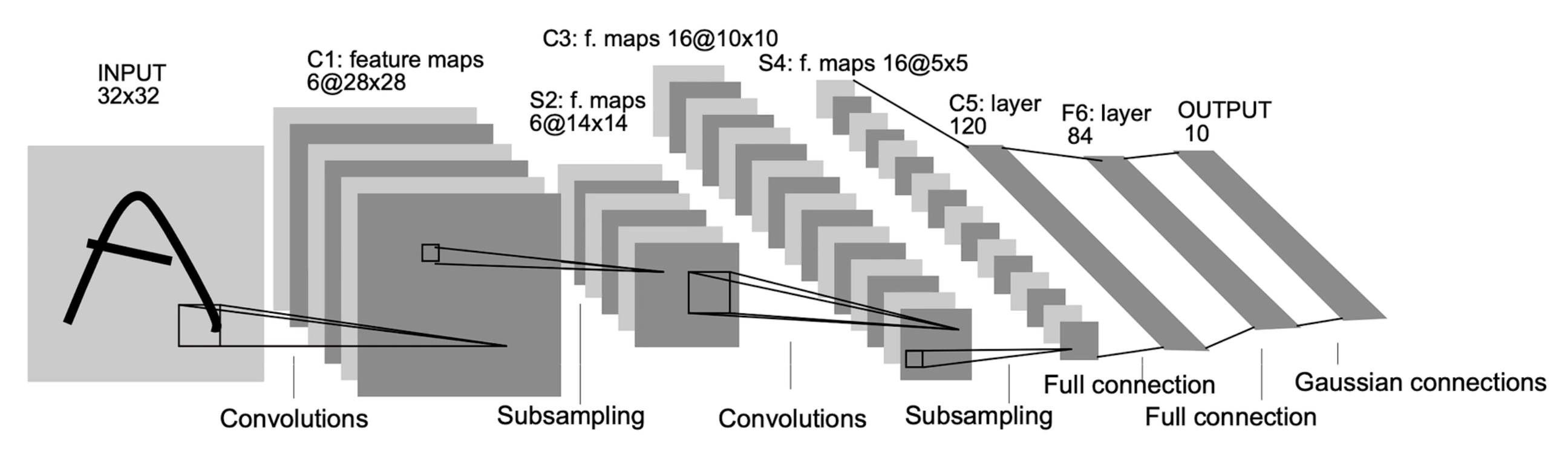
- 卷积核:5*5,步幅:1,填充:0
- 池化核:2*2,步幅:2,填充:0
模型训练
python
import os
from datetime import datetime
import numpy as np
import pandas as pd
import pathlib
import matplotlib.pyplot as plt
import keras
from keras.layers import Dense, Flatten, Conv2D, MaxPool2D
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 读数数据
train_data = pathlib.Path('./data/train')
test_data = pathlib.Path('./data/test')
# 给数据类别放置到列表
label = np.array(['0', '1', '2'])
# 把图片设置成 32*32
img_size = 32
batch_size = 16
# 数据归一化生成器
img_generator = keras.preprocessing.image.ImageDataGenerator(rescale=1.0 / 255)
# 生成训练数据
train_data_gen = img_generator.flow_from_directory(
directory=train_data,
batch_size=16,
shuffle=True,
target_size=(img_size, img_size),
classes=list(label)
)
test_data_gen = img_generator.flow_from_directory(
directory=test_data,
batch_size=16,
shuffle=True,
target_size=(img_size, img_size),
classes=list(label)
)
# 使用Keras搭建CNN模型
model = keras.Sequential([
# 卷积层
# filters: 卷积核数量
# kernel_size: 卷积核尺寸
Conv2D(filters=6, kernel_size=5, input_shape=(32, 32, 3), activation='relu'),
# 池化层
# pool_size: 池化窗口尺寸
# strides: 步长
MaxPool2D(pool_size=(2, 2), strides=2),
# 卷积层
Conv2D(filters=16, kernel_size=5, activation='relu'),
# 池化层
MaxPool2D(pool_size=(2, 2), strides=2),
# 平展层
Flatten(),
# 全连接层
Dense(84, activation='relu'),
Dense(3, activation='softmax')
])
model.compile(loss="categorical_crossentropy", optimizer="Adam", metrics=["accuracy"])
his = model.fit(train_data_gen, epochs=40, validation_data=test_data_gen)
# 保存模型
timestamp = datetime.now().strftime('%Y-%m-%d-%H:%M:%S')
os.makedirs(f"./log_{timestamp}")
model.save(f"./log_{timestamp}/model.h5")
# loss对比图
plt.plot(his.history['loss'], 'b', label='训练集损失')
plt.plot(his.history['val_loss'], 'r', label='验证集损失')
plt.legend()
plt.savefig(f"./log_{timestamp}/loss.png")
plt.show()
# 准确率对比图
plt.plot(his.history['accuracy'], 'b', label='训练集准确率')
plt.plot(his.history['val_accuracy'], 'r', label='验证集准确率')
plt.legend()
plt.savefig(f"./log_{timestamp}/accuracy.png")
plt.show()模型预测
tf.expand_dims 用于在输入数据的最前面添加一个维度,将原本的 3 维数据(长、宽、通道)扩充为 4 维数据(批大小、长、宽、通道)。
因为大部分深度学习模型的输入数据都是以批量的形式进行处理的,即使你只有一张图像作为输入,也需要将其扩充为一个大小为 1 的批量。
python
import tensorflow as tf
import cv2
import keras
import numpy as np
# 给数据类别放置到列表
label = np.array(['0', '1', '2'])
img_size = 32
# 导入模型
model = keras.models.load_model("./log_2024-02-02-12:24:42/model.h5")
# 数据预处理
src = cv2.imread("./data/test/0/43.jpg")
scr = cv2.resize(src, (img_size, img_size)).astype("int32")
scr = scr / 255
# 扩充数据维度:添加一个batch_size维度
test_img = tf.expand_dims(scr, 0)
# 模型预测
pre_val = model.predict(test_img)
score = pre_val[0]
print(f"预测值:{label[np.argmax(score)]}")
print(f"预测概率:{np.max(score) * 100}")